Machine Learning for Survival Analysis
Abstract:
Due to the advancements in various data acquisition and storage technologies, different disciplines have attained the ability to not only accumulate a wide variety of data but also to monitor observations over longer time periods. In many real-world applications, the primary objective of monitoring these observations is to estimate when a particular event of interest will occur in the future. One of the major difficulties in handling such problem is the presence of censoring, i.e., the event of interests is unobservable in some instance which is either because of time limitation or losing track. Due to censoring, standard statistical and machine learning based predictive models cannot readily be applied to analyze the data. An important subfield of statistics called survival analysis provides different mechanisms to handle such censored data problems. In addition to the presence of censoring, such time-to-event data also encounters several other research challenges such as instance/feature correlations, high-dimensionality, temporal dependencies, and difficulty in acquiring sufficient event data in a reasonable amount of time. To tackle such practical concerns, the data mining and machine learning communities have started to develop more sophisticated and effective algorithms that either complement or compete with the traditional statistical methods in survival analysis. In spite of the importance of this problem and relevance to real-world applications, this research topic is scattered across various disciplines. In this tutorial, we will provide a comprehensive and structured overview of both statistical and machine learning based survival analysis methods along with different applications. We will also discuss the commonly used evaluation metrics and other related topics. The material will be coherently organized and presented to help the audience get a clear picture of both the fundamentals and the state-of-the-art techniques.
Final
version of the TUTORIAL SLIDES
Complete Taxonomy Datasets Software Packages
Tutorial Coverage:
This tutorial is based on our recent survey article [1]. Overall, the tutorial consists of the following four parts. Reference: Presenter
BIOs:
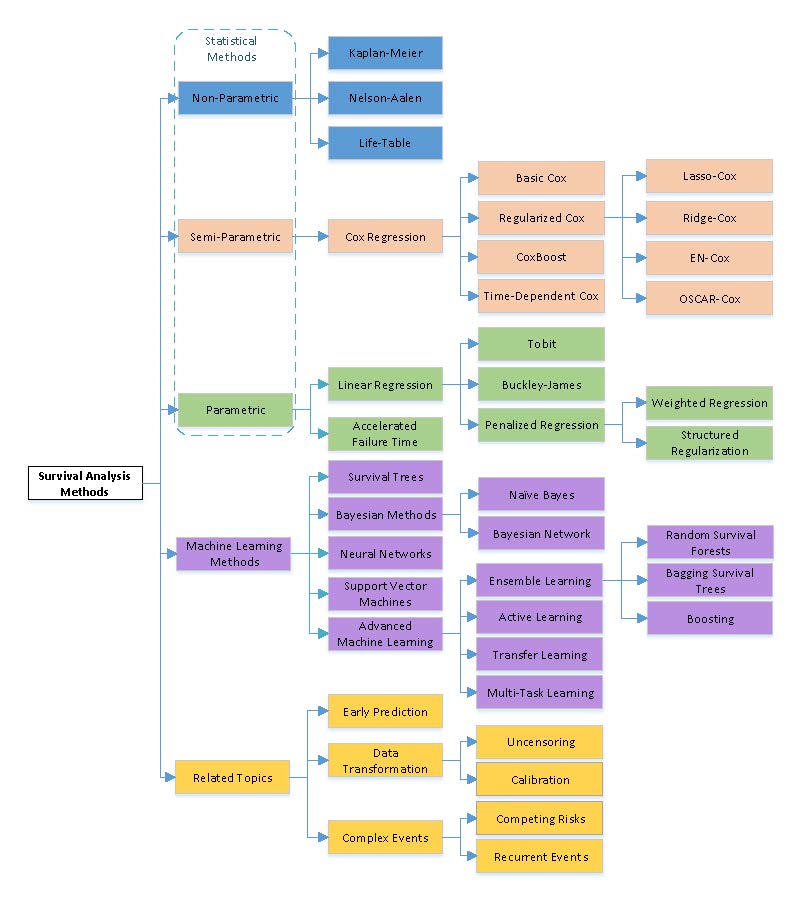
(1) Motivation for survival analysis using various real-world applications and a detailed taxonomy of the survival analysis methods (provided in the Taxonomy figure given above) that were developed in the traditional statistics as well as in the machine learning communities.
(2) Traditional statistical methods which include non-parametric, semi-parametric, and parametric models. Cox regression model, which falls under the semi-parametric models and is widely used to solve many real-world problems, will be discussed in detail.
(3) Various machine learning algorithms developed to handle survival data. In addition to discussing about the basic machine learning algorithms (such as trees, Bayesian methods, neural networks, support vector machines), this tutorial will also provide a lot of details and insights about different kinds of advanced machine learning algorithms such as ensemble learning, active learning, transfer learning and multi-task learning for dealing with survival data.
(4) Topics related to survival analysis such as early prediction and residual analysis. Various data pre-processing approaches such as uncensoring and calibration which can be used in conjunction with any existing survival methods will be described. Finally, the tutorial will end with a discussion on complex events such as competing risks and recurring events.
Chandan K. Reddy is an Associate Professor in the Department of Computer Science at Virginia Tech. He received his Ph.D. from Cornell University and M.S. from Michigan State University. His primary research interests are Data Mining and Machine Learning with applications to Healthcare Analytics, Bioinformatics and Social Network Analysis. His research is funded by the National Science Foundation, the National Institutes of Health, the Department of Transportation, and the Susan G. Komen for the Cure Foundation. He has published over 80 peer-reviewed articles in leading conferences and journals including SIGKDD, WSDM, ICDM, SDM, CIKM, TKDE, DMKD, TVCG, and PAMI. He received several awards for his research work including the Best Application Paper Award at ACM SIGKDD conference in 2010, Best Poster Award at IEEE VAST conference in 2014, Best Student Paper Award at IEEE ICDM conference in 2016, and was a finalist of the INFORMS Franz Edelman Award Competition in 2011. He is a senior member of the IEEE and life member of the ACM.
Yan Li is a Postdoc fellow in the Department of Computational Medicine and Bioinformatics at University of Michigan, Ann Arbor. He received his Ph.D. and M.S. from Wayne State University and B.S. from Xidian University. His primary research interests are Data Mining and Machine Learning with applications to Healthcare Analytics and Bioinformatics. His research works have been published in leading conferences and journals including SIGKDD, ICDM, WSDM, SDM, CIKM, DMKD, and Information Science.
{kind=link}