Index of /TUTORIAL/Survival
Name
Last modified
Size
Description
Parent Directory
-
Slides.pdf
2017-08-14 12:05
3.2M
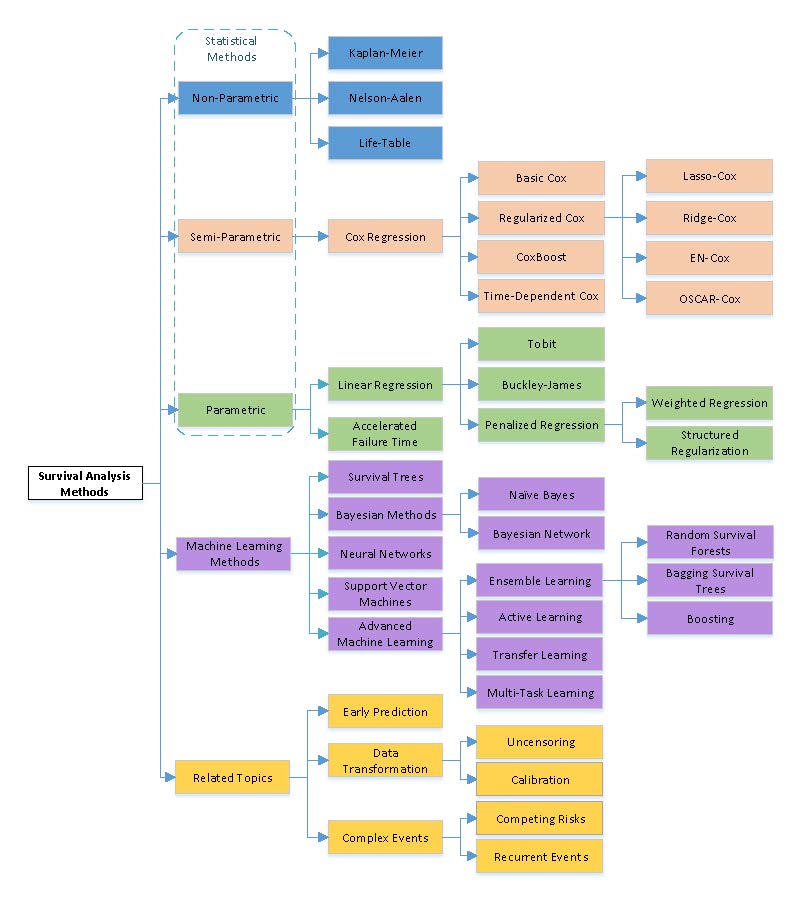
Taxonomy.jpg
2017-04-09 00:11
82K
index.htm
2017-08-19 18:24
43K
{kind=link}